How AI Models Are Getting Smarter
How AI models are getting smarter is a question that’s captivating the tech world. It’s not just about faster processors; it’s a confluence of factors pushing the boundaries of artificial intelligence. From the sheer volume of data being fed to these models to the increasingly sophisticated architectures powering them, the advancements are nothing short of breathtaking. We’re witnessing a rapid evolution, a true intelligence explosion, driven by breakthroughs in training techniques, computational power, and a growing focus on making AI more transparent and trustworthy.
This post dives into the key drivers behind this remarkable progress. We’ll explore how massive datasets, innovative model designs, refined training methods, and enhanced computing resources are all working together to create AI systems that are not only more powerful but also more reliable and understandable. Get ready to unravel the mysteries behind this exciting technological leap!
Enhanced Training Techniques

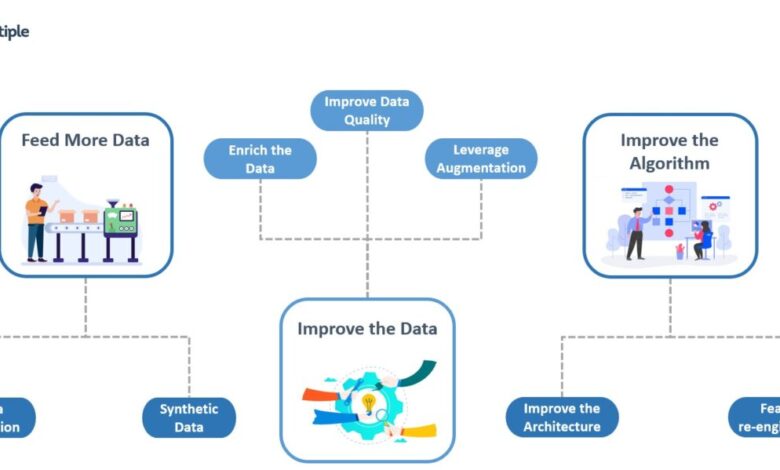
The rapid advancements in AI are not solely due to increased computational power; a significant factor is the development of increasingly sophisticated training techniques. These techniques allow us to train more accurate, efficient, and robust AI models, pushing the boundaries of what’s possible. This section delves into some of the key methods driving this progress.
Transfer Learning
Transfer learning is a powerful technique that leverages knowledge gained from solving one problem to improve performance on a related, but different, problem. Instead of training a model from scratch on a new dataset, we can utilize a pre-trained model – often one trained on a massive dataset like ImageNet for image recognition or a large text corpus for natural language processing.
This pre-trained model already possesses a rich understanding of fundamental features or patterns. We then fine-tune this model on a smaller, task-specific dataset, significantly reducing training time and data requirements. For example, a model trained to identify cats and dogs could be adapted to identify different breeds of dogs with relatively little additional training data. This drastically cuts down on the computational resources and time needed to achieve high accuracy.
The pre-trained model provides a strong foundation, accelerating the learning process for the new task.
Reinforcement Learning Applications, How ai models are getting smarter
Reinforcement learning (RL) is a paradigm where an AI agent learns to make optimal decisions through trial and error. The agent interacts with an environment, receives rewards for desirable actions and penalties for undesirable ones, and learns a policy that maximizes its cumulative reward. RL has seen remarkable success in areas like game playing (AlphaGo, AlphaZero), robotics, and resource management.
For example, in robotics, an RL agent might learn to navigate a complex environment by receiving positive rewards for reaching a goal and negative rewards for collisions or exceeding time limits. The agent iteratively refines its actions based on the feedback it receives, leading to improved performance over time. This approach allows for the development of AI systems capable of adapting to dynamic and unpredictable situations.
AI models are rapidly improving, learning to analyze complex data with increasing accuracy. This raises questions about how these advancements can be applied to real-world problems, like tackling financial crime – a key area in the upcoming election, as explored in this insightful article: will labour be better at tackling dirty money than the tories. Ultimately, the smarter AI gets, the more effective tools we’ll have to fight corruption and improve transparency.
The potential applications are truly exciting.
Optimization Algorithms
The efficiency and accuracy of AI model training are heavily influenced by the choice of optimization algorithm. These algorithms adjust the model’s parameters (weights and biases) to minimize a loss function, which measures the difference between the model’s predictions and the actual values. Two widely used algorithms are Stochastic Gradient Descent (SGD) and Adam. SGD iteratively updates the parameters based on the gradient of the loss function calculated on a small batch of data.
Adam, an adaptive optimization algorithm, incorporates momentum and adaptive learning rates, often leading to faster convergence and improved performance, especially in complex, high-dimensional spaces. The selection of an appropriate optimization algorithm depends on the specific characteristics of the dataset and the model architecture. While Adam often provides a good starting point due to its robustness, SGD with carefully tuned hyperparameters can sometimes achieve superior results.
Various Training Techniques and Their Properties
The effectiveness of training an AI model often hinges on employing the right techniques. Choosing the appropriate method depends heavily on the nature of the data and the desired outcome. Here’s a summary of some key approaches:
- Supervised Learning: The model is trained on labeled data, where each data point is associated with a known output. Advantages: Relatively straightforward to implement, often yields high accuracy. Disadvantages: Requires large amounts of labeled data, can be prone to overfitting if the data is not representative.
- Unsupervised Learning: The model is trained on unlabeled data, learning underlying patterns and structures. Advantages: Can uncover hidden relationships in data, useful when labeled data is scarce. Disadvantages: Interpretation of results can be challenging, performance can be less predictable than supervised learning.
- Reinforcement Learning: The model learns through interaction with an environment, receiving rewards or penalties based on its actions. Advantages: Suitable for complex decision-making problems, can adapt to dynamic environments. Disadvantages: Can be computationally expensive, requires careful design of the reward function.
- Semi-Supervised Learning: Combines labeled and unlabeled data for training. Advantages: Can leverage the benefits of both supervised and unsupervised learning, useful when labeled data is limited. Disadvantages: Requires careful consideration of how to effectively combine labeled and unlabeled data.
Improved Computational Resources
The relentless march towards more intelligent AI models isn’t just about clever algorithms; it’s fundamentally driven by the ever-increasing power of the hardware that fuels them. The ability to train larger, more complex models, and do so faster, is directly tied to advancements in computational resources. This means faster training times, leading to quicker iterations and ultimately, smarter AI.GPUs and specialized hardware have revolutionized AI model training.
The sheer number of calculations involved in training even moderately complex models is astronomical. Traditional CPUs, while versatile, simply can’t keep pace.
The Role of GPUs and Specialized Hardware
Graphics Processing Units (GPUs), initially designed for rendering images, possess massively parallel architectures ideally suited for the matrix multiplications and other computationally intensive tasks at the heart of AI algorithms. A single GPU can perform thousands of calculations simultaneously, dramatically accelerating training compared to a CPU. Furthermore, specialized hardware like TPUs (Tensor Processing Units) from Google are designed specifically for machine learning workloads, offering even greater performance gains.
AI models are advancing at an incredible pace, learning and adapting faster than ever before. This rapid progress makes me wonder about the implications – for instance, how effectively AI could be used to track the massive undertaking described in this article, ice issues smartphones to 255602 illegal border crossers cost is 89 5 million a year , and optimize resource allocation.
Ultimately, smarter AI could lead to more efficient solutions, but also raises important ethical questions about data privacy and surveillance.
These specialized chips are optimized for the specific mathematical operations required for AI, resulting in significantly faster training times and lower energy consumption. For example, training a large language model that might take weeks on a cluster of high-end CPUs could be completed in days, or even hours, using a cluster of specialized hardware like TPUs.
AI models are rapidly improving their ability to analyze complex datasets, leading to breakthroughs in various fields. This analytical power is crucial for understanding nuanced trends, like the concerning data presented in this article about COVID-19 mortality: high percentage of covid deaths had 3rd shot more excess deaths after 4th shot. Such analyses highlight the need for sophisticated AI to sift through vast amounts of information and uncover potentially hidden patterns that inform future health strategies.
Ultimately, smarter AI means better data interpretation and more effective decision-making.
The Impact of Cloud Computing
Cloud computing has democratized access to high-performance computing resources. Previously, training sophisticated AI models required massive upfront investments in expensive hardware infrastructure. Now, researchers and developers can access powerful GPU clusters and TPUs through cloud providers like AWS, Google Cloud, and Azure, paying only for the compute time they use. This scalability is crucial: researchers can easily scale their computing resources up or down depending on their needs, making it easier to experiment with different model architectures and sizes without significant financial constraints.
This accessibility has fostered a boom in AI innovation, enabling smaller teams and startups to compete with larger organizations.
Increased Computational Power and Model Complexity
The exponential increase in computational power has directly led to the development of significantly larger and more complex AI models. Larger models, with more parameters, can learn more intricate patterns and relationships in data, leading to improved accuracy and performance. For example, the early versions of large language models had millions of parameters; now, we see models with hundreds of billions, or even trillions, of parameters.
This increase in scale wouldn’t have been possible without the parallel processing power offered by GPUs and specialized hardware, combined with the scalability provided by cloud computing.
Training Time Comparison Across Computational Resources
Imagine a simple bar chart. The X-axis represents different computational resources: a single CPU, a cluster of CPUs, a cluster of GPUs, and a cluster of TPUs. The Y-axis represents the time taken to train a specific AI model (e.g., a large language model with 100 million parameters). The bar for the single CPU would be significantly longer than the others, perhaps representing weeks of training time.
The cluster of CPUs would be shorter, maybe a few days. The cluster of GPUs would be even shorter, perhaps a day or less. Finally, the bar for the cluster of TPUs would be the shortest, possibly just a few hours. This visual representation highlights the dramatic impact of different computational resources on training efficiency.
Focus on Explainability and Interpretability: How Ai Models Are Getting Smarter

The relentless march towards more intelligent AI models necessitates a parallel advancement in understanding how these models arrive at their conclusions. Simply having a highly accurate AI isn’t enough; we need to knowwhy* it’s making the decisions it is. This is where explainability and interpretability become crucial, transforming opaque “black boxes” into more transparent and trustworthy systems.Explainability and interpretability in AI involve techniques designed to shed light on the internal workings of a model, making its decision-making process understandable to humans.
This isn’t just about satisfying curiosity; it’s about building trust, identifying and mitigating biases, and ultimately improving the reliability and safety of AI systems. Without this understanding, deploying complex AI models in critical applications like healthcare or finance would be irresponsible.
Methods for Enhancing Model Transparency
Several methods exist to improve the transparency of AI models. These range from simple visualizations of model parameters to more sophisticated techniques that analyze the model’s internal representations. For instance, feature importance analysis helps pinpoint which input features most heavily influence the model’s output. This can be visualized through heatmaps, where features are ranked based on their contribution.
Another approach involves using simpler, inherently interpretable models like linear regression or decision trees, particularly when understanding the model’s reasoning is paramount. More complex models, like deep neural networks, can be probed using techniques like Layer-wise Relevance Propagation (LRP) to trace the influence of input features on the final prediction. These methods offer varying degrees of insight, and the best approach depends on the specific model and application.
Techniques for Interpreting Model Predictions and Identifying Biases
Interpreting model predictions involves examining the model’s reasoning behind its output. For example, if a loan application is rejected, an interpretable model might highlight specific factors (e.g., credit score, debt-to-income ratio) that led to the decision. Identifying biases is equally important. Biases can stem from skewed training data, leading the model to make unfair or discriminatory predictions.
Techniques like fairness-aware algorithms and bias detection tools help identify and mitigate these biases. For example, if a facial recognition system consistently misidentifies individuals with darker skin tones, this signals a bias that needs to be addressed through data augmentation or algorithmic adjustments. Analyzing the model’s predictions across different demographic groups helps reveal potential biases and inequalities.
Benefits of Explainable AI (XAI) in Building Trust and Improving Model Reliability
Explainable AI (XAI) is not just a technical endeavor; it’s a critical step towards building trust and confidence in AI systems. When users understand how an AI arrives at its conclusions, they are more likely to accept and trust its decisions. This is particularly important in high-stakes applications, where transparency is essential for accountability and regulatory compliance. Furthermore, XAI improves model reliability by facilitating the detection and correction of errors.
By understanding the model’s reasoning, developers can identify flaws in the model’s logic or training data, leading to improved model performance and reduced risk. This proactive approach to error detection significantly enhances the overall reliability and robustness of AI systems.
Examples of Explainability Techniques Enhancing Understanding of AI Decision-Making
Consider a medical diagnosis system using XAI. Instead of simply providing a diagnosis, the system could also explain the reasoning behind its decision, highlighting the specific medical images and patient data that led to the conclusion. This allows doctors to review the AI’s findings and validate the diagnosis, fostering collaboration and improving patient care. Similarly, in fraud detection, an explainable model could identify the specific transactions and user behaviors that triggered a fraud alert, providing valuable insights for investigators.
These examples demonstrate how explainability techniques can enhance the understanding of AI decision-making, ultimately leading to more responsible and effective AI deployment across diverse domains.
The Role of Meta-Learning

Meta-learning, often described as “learning to learn,” is revolutionizing the field of artificial intelligence. It focuses on equipping AI models with the ability to adapt quickly to new tasks and datasets with minimal training data, significantly improving their generalization capabilities. This contrasts sharply with traditional machine learning approaches which require vast amounts of data for each specific task.Meta-learning allows AI models to learn more effectively by focusing on the process of learning itself.
Instead of directly learning a specific task, a meta-learner acquires knowledge about how to learn new tasks efficiently. This knowledge is then leveraged to rapidly adapt to unseen data or problems. Think of it like learning how to learn a new language – instead of just memorizing vocabulary for one language, meta-learning is about developing strategies for learning
any* new language quickly.
Meta-learning Approaches
Meta-learning encompasses a variety of techniques. One prominent approach is Model-Agnostic Meta-Learning (MAML), which aims to find model parameters that generalize well across multiple tasks. MAML achieves this by training a model on a diverse set of tasks, optimizing its parameters such that a few gradient steps on a new task are sufficient to achieve high performance. Another approach involves using recurrent neural networks (RNNs) to learn a sequence of learning steps, effectively building a learning algorithm that can adapt to different scenarios.
These methods represent different ways to achieve the core goal: improving the efficiency and effectiveness of the learning process itself.
Comparison with Traditional Machine Learning
Traditional machine learning typically involves training a model on a large dataset for a specific task. This approach suffers from several limitations. First, it requires enormous amounts of labeled data, which can be expensive and time-consuming to acquire. Second, the trained model often performs poorly on tasks that differ significantly from the training data (lack of generalization). Meta-learning addresses these issues by focusing on learning strategies rather than task-specific knowledge.
A meta-learner, once trained, can quickly adapt to new tasks with minimal data, showcasing significantly improved generalization and efficiency compared to traditional approaches. For example, a traditional image classifier might require millions of images to accurately classify cats and dogs, while a meta-learned model might only need a few hundred examples to achieve comparable performance on a new breed of cat or dog.
The Impact of Meta-Learning on Future AI Development
Meta-learning holds the key to unlocking truly adaptable and intelligent AI systems. By enabling models to learn efficiently from limited data and generalize effectively to new tasks, meta-learning will pave the way for more robust, versatile, and human-like AI capabilities. This will have profound implications across various domains, from personalized medicine and robotics to natural language processing and autonomous driving.
The journey into how AI models are getting smarter reveals a fascinating interplay of data, algorithms, and computing power. It’s a testament to human ingenuity and our relentless pursuit of creating intelligent machines. While challenges remain, the advancements we’ve discussed point towards a future where AI plays an even more significant role in our lives, transforming industries and solving complex problems in ways we can only begin to imagine.
The path ahead is paved with innovation, and the smarter AI becomes, the more exciting the possibilities become.

